理论篇
什么时候用动态规划
一个模型三个特征
模型:多阶段决策最优解模型
解决问题的过程,需要经历多个决策阶段。每个决策阶段都对应着一组状态。然后我们寻找一组决策序列,经过这组决策序列,能够产生最终期望求解的最优值。
最优子结构:
最优子结构指的是,问题的最优解包含子问题的最优解。反过来说就是,我们可以通过子问题的最优解,推导出问题的最优解。
无后效性:
无后效性有两层含义,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。
重复子问题:
不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。
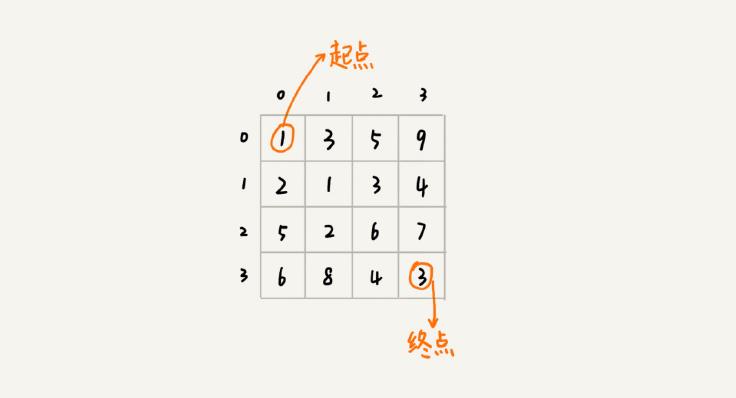
举个例子——棋盘问题
一个机器人从4*4的棋盘的左上角走到右下角,每次走一个,且只能向下或向右,每个格子有自己的权值,请问怎样走权值总和最小?
这就完全符合上述的情况(每走一格就代表一个阶段,每个阶段对应一个状态集合,最优路径一定由最优子路径组成;我们不关心来的路线,只关心经过路线的权值和;不同路径在相同阶段会有重复)
两种解题思路
状态转移表法
我们先画出一个状态表。状态表一般都是二维的,所以你可以把它想象成二维数组。其中,每个状态包含三个变量,行、列、数组值。我们根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态。最后,我们将这个递推填表的过程,翻译成代码,就是动态规划代码了。
回溯、贪心与动态规划
回溯
回溯算法是个“万金油”。基本上能用的动态规划、贪心解决的问题,我们都可以用回溯算法解决。回溯算法相当于穷举搜索。穷举所有的情况,然后对比得到最优解。不过,回溯算法的时间复杂度非常高,是指数级别的,只能用来解决小规模数据的问题。对于大规模数据的问题,用回溯算法解决的执行效率就很低了。
动态规划
尽管动态规划比回溯算法高效,但是,并不是所有问题,都可以用动态规划来解决。能用动态规划解决的问题,需要满足三个特征,最优子结构、无后效性和重复子问题。在重复子问题这一点上,动态规划和分治算法的区分非常明显。分治算法要求分割成的子问题,不能有重复子问题,而动态规划正好相反,动态规划之所以高效,就是因为回溯算法实现中存在大
量的重复子问题。贪心算法
贪心算法实际上是动态规划算法的一种特殊情况。它解决问题起来更加高效,代码实现也更加简洁。不过,它可以解决的问题也更加有限。它能解决的问题需要满足三个条件,最优子结构、无后效性和贪心选择性(这里我们不怎么强调重复子问题)。其中,最优子结构、无后效性跟动态规划中的无异。
“贪心选择性”的意思是,通过局部最优的选择,能产生全局的最优选择。每一个阶段,我们都选择当前看起来最优的决策,所有阶段的决策完成之后,最终由这些局部最优解构成全局最优解。
实战篇
机器人达到指定位置方法数
【题目】
假设有排成一行的N个位置,记为1~N,N一定大于等于2.开始时机器人在其中的M位置上。机器人可以往左走或者往右走,如果机器人来到1位置,那么下一步只能往右来到2位置;如果机器人来到N位置,那么下一步只能往左来到N-1位置。规定机器人必须走K步,最终能来到P位置的方法有多少种?
【举例】N = 5,M = 2, K = 3, P = 3;
【解答】我们说过,所有的动态规划问题,都可以用回溯问题来解决,那么我们完全可以先利用递归的思路来想一下思路,然后过渡到动态规划,实际上,这种暴力递归到动态规划的优化对于很多问题都适用。
暴力递归
其实暴力递归就是回溯,我们直接上代码
1 | /** |
看见没,回溯解决问题的代码就是那么简单,可是代码的简洁是用时间复杂度换来的。所以哈,面试的时候,如果面试官向你提了一个算法题,你可以先用回溯拖一下,因为回溯是很容易想到的解决问题的算法,然后我们再对他进行优化。
优化为动态规划
在这之前,我们已经能确定了这个问题是具有无后效性的。
那么套路大体步骤如下:
- 找到什么可变参数可以代表一个递归状态,也就是哪些参数一旦确定,返回值就确定了。
- 把可变参数的所有组合映射成一张表,有一个可变参数就是一维表,2个可变参数就是二维表…
- 最终答案要的是表中的哪个位置,在表中标出。
- 根据地轨过程的base case,把这张表最简单,最不需要依赖其他位置的那些位置填好值。
- 根据递归过程的非base case的部分,也就是分析表中的普遍位置需要怎么计算得到,那么这张表的填写顺序就确定了。
- 填好表,返回最终答案在表中的位置。
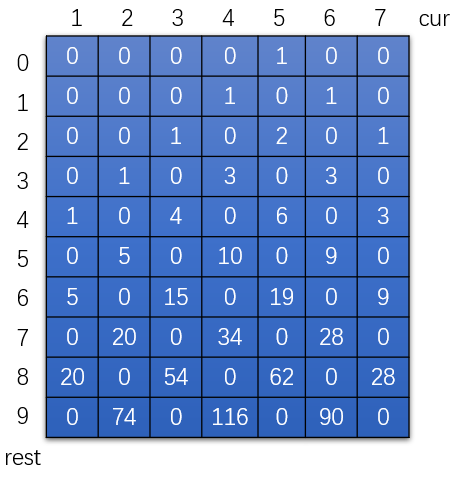
针对于这道题我们可以套用一下:N = 7,M = 5, K = 9, P = 4;
walk函数中,可变参数cur,rest一旦确定,返回值也就确定了。- 如果可变参数
cur和rest组合的所有可能情况组成一张表,这张表便装下了所有的返回值。如下图所示
最终要求的位置,标出来。在这里我们最终位置是dp[9][4],我们已经用星号在上图标出来了位置。
base case指问题的规模小到什么程度,就不需要划分子问题,很明显指的是代码如下的情况,表现在二维数组下图所示
1
2
3if(reset == 0){
return cur == P ? 1 : 0;
}
- 那么剩下的代码对应的就是非base case,那么如何填写呢?我们要找到下一行是怎样计算得到的,很明显,是有旁边的两个格子相加得出来的(边界条件除外),很容易得出下表
代码
最后,我们来看一下动态规划的代码
1 | public int ways2(int N, int M, int K, int P){ |
参照之前的回溯,还是很容易看懂的吧,实际就是维护了一个二维数组,实际上,我们的二维数组是可以继续优化的,毕竟当我们走到第3步的时候,我们并不关心第一步走的情况,那一层数据对我们来说就是没有的用的。
数组压缩
当然,我们可以将二维数组压缩为一维数组,毕竟是无后效性。我们完全可以维持更新第i步时的位置信息,注意更新的时候保存中间值,防止更新的时候覆盖掉
1 | public int ways2(int N, int M, int K, int P){ |
总结
以上就是我对动态规划的一些梳理总结,希望大家看完这篇文章之后对于动态规划问题能有一个自己的判别,动态问题的难点在于识别出他的模型,建立你心中的那个表,解锁了动态规划问题之后,我们的算法库会多出来更多关于它的问题,希望大家持续关注。
我们下期再见!
附录:本文参考自《程序源代码面试指南(第二版)》、极客时间——《数据结构与算法之美》。